
Chris Butler, Lead Product Manager at Google, gave this presentation at the Product-Led Summit in San Francisco in 2023.
Hello, everybody, thank you very much for being here. I work for the core machine learning group inside of Google, and what we do is basically build everything; we help with applied solutions for different product areas like search, ads, maps, and any of those groups, down to the frameworks and services. That includes things like TensorFlow and TensorBoard, all that type of stuff.
We also end up owning a lot of the ways that people internally end up using accelerators like TPUs and GPUs.
And then we also do chip co-design, which is how you lay out the TPUs of the future for future machine learning workloads.
One question I get asked a lot of the time is, “How should I use machine learning inside my product?”
Then there’s a second question I get from a lot of product managers, which is, “How do I train up to be an AI product manager?” And this talk is going to be a bit more about what the reality of this is, rather than what this perception is that's starting to be built inside of the industries today.
- What does PM specialization look like?
- Navigating the emergence of mobile
- Specialization based on uncertainty
- What nuance is involved for AI PMs right now?
- Having better discussions between tech and non-tech
What does PM specialization look like?
Let's start with what specialization even means within the PM world.
There are people who end up calling themselves platform PMs, growth PMs, and that type of thing. But I think there are four main ways that we end up talking about specialization.
The first one is if we really require different skill sets. In product management, I believe that overall, we have to be good at managing uncertainty. We have to be able to be good decision facilitators, we have to be able to build a line, and we have to be able to communicate. Those are skills that we build over time.
And I’d ask, for these specializations, do we require different skills in some way?
The second thing is competencies. I see skills and competencies as overlapping, but sometimes they're more meta in some way.
I also think that the different expectations about what you're supposed to do in your day-to-day job could mean that you're a specialization that's not just product management.
And then finally, if you're in completely different organizations. We usually work in cross-functional teams, managing up to some type of GM. Are you on a different ladder or a different part of that organization as part of this?
So, let's keep these things in mind as we start to talk about what it means to actually be an AI PM.
Frank Tisellano works at Google as well, and he asked this really good question, which is:
‘If we're going to talk about the API PM, is there such thing as an MVC framework PM? An HTML PM? Or a NoSQL database PM?’
I tend to agree. I don't want to give away too much of my talk, but I think we get caught up a lot of the time as product managers in the technical world that we're helping, when the reality is that we’re supposed to be more about customers, we're supposed to be about outcomes, and about the impact that we end up making. And that’s almost rarely about the technology.
Navigating the emergence of mobile
I want to bring about a story from my background, which is more about this emergence of mobile.
I worked at KAYAK as a hybrid BD and product person. I was brought in to help figure out the way that mobile would actually work for us, and this was at the time when desktop search for KAYAK was starting to be eclipsed by mobile. In fact, when I was there, about a month and a half after that, mobile became a majority share of usage within KAYAK.
And within that world, we’d see a lot of interesting changes in behavior. People were doing more searches, not just on mobile in general, but per capita, they were doing more searches.
As we started to dig into why that was happening, I got hired as a mobile PM and we were trying to do all this very mobile-specific stuff. But what we started to realize once we connected the dots across mobile and desktop, and not just mobile apps, but also web, was that people were doing much earlier searches about the way that they were thinking about travel with mobile than they were with desktop.
They weren’t buying more travel. Just because you want a mobile phone, it doesn't change the job to be done of a person wanting to get relaxation, to go to a business meeting, or fly to a wedding or something like that.
So it didn't change any of that. What it did change though was their accessibility to information and the way that they used that information in an early stage to be able to make a decision.
After a couple of years, there was no such thing as a mobile channel. In fact, what we started to realize was that it didn't matter which channel was part of it, and that's what omnichannel ended up being, by the way.
It didn't matter whether it was mobile or desktop or whatever, it was an experience for a person. That's why we tend to find that the hierarchies within product management organizations tend to focus more on products that are about a particular customer, or if there are multiple customers, you'll find that you start to think about that experience like less of a persona, and more of a journey.
So, for me, I started to think about this idea of specialization, especially around uncertainty.
Specialization based on uncertainty
Something I talk about a lot is this project I’m a part of called ‘the uncertainty project,’ which is writing about decision-making and strategy.
In this world of uncertainty, when we first get started on something, we're highly uncertain about the way it should work. Most of the time today, though, we actually operate somewhere in the middle. We have to deal with the uncertainty and complexity of the world, and we have to deal with these questions about what’s actually going on.
However, it's certain enough that we can have our projects project managed, that we can actually release something, and we can make an impact in some way. We're more likely to make a good impact ideally than we are to make a bad impact, but we're kind of in the middle right now if you're just a PM.
I think there are highly uncertain timeframes when we're still trying to figure out the rules of how we actually do something, and I'll talk about the nuance here. I think that's something I want to talk about: what is the nuance of AI and machine learning? But the reality is, this mobile PM, this AI PM, any of these types of PMS that are in highly uncertain areas, they're just on the way towards becoming a regular PM.
Now, there's another side of the spectrum, which is that I've worked for a lot of teams where there's almost zero uncertainty in what they're doing. They’re a platform that has existed for many years, they need to fix bugs, they need to make sure that it continues to be performant, and they need to make sure it continues to work.
There are no PMs in this world, or if there are PMs they’re not doing very much. They're trying to find something else to build.
So, when it comes to this AI PM, I don't think this is going to be a thing for a very long time. I think maybe for a year or two at most at this point.
It's just going to be a PM, but that doesn't mean that there isn’t nuance. There's always nuance in every context that we end up joining.
Every time that you join a particular team as a PM, you need to figure out how you help the people within that team, rather than just doing the job. There's no such thing as joining a team and saying, “Here's the exact framework we're going to use, here's the way we're going to do development, and here's all the stuff I need from you, so just get out of the way.” That person is always going to fail.

What nuance is involved for AI PMs right now?
So, let's talk a bit more about the nuance within the AI PM world. What nuance is involved right now? There are three things that I want to talk through:
One, is data, and what does that mean? Two, is training, and what does that mean? And then finally, what do we talk about when we're talking about the experience that we're actually building for our customers and how that changes with AI and machine learning?
Data
First, with data, there are a couple of key tenants that I like to talk about. The first one is garbage in, garbage out (GIGO). Whereas before, we maybe had to worry about customer data creating a bad circumstance for our products, we're now using data before customers get involved at all in some cases.
So, creating and curating the right type of data is very, very important in this type of role.
All of the bias, fairness, and other types of responsible AI issues come out through data most of the time. There's no such thing as a model architecture that’ll reduce bias. There are only data sets and the way that you end up training them that creates a fair or balanced model in a way that you feel is appropriate.
And I want to be very clear here; we talk about bias inside of the machine learning world, but there's positive, negative, and neutral bias. Everything we do is biased in some way, it's just about whether it’s bad for the people that we're trying to solve problems for or not.
The next thing is that finding the data is a really, really big issue. A lot of the time, you may not have enough of it, and if that's the case, you then actually have to start creating it. And there are a lot of issues that start to come up around synthetic data and the way that we end up creating and curating that type of information.
The final thing I want to bring up is this idea around regulation and consent of collection. This is something that qualitative user researchers have been dealing with for a very long time.
Data is valuable. It’s maybe the new oil. But also, you don't want to live around a lot of barrels of oil. It's toxic in some ways. So you have to be very careful in the ways that you end up collecting this data.
I think it's very much related to another thing that I think is quite interesting.
We're living in this world of hype around generative systems, systems that can create text, images, videos, and 3D models, just from having something described to them.
When we talk about data, it ends up getting very weird when we start to think about possible futures. This is something called a scenario planning exercise, where there's one very big uncertainty, which is something called embeddings. Once data has gone and trained a model, you have an embedding.
But does this or does this not generate derivative work? Derivative work is a copyright term that means, is it the same thing that we just created from something else? Or is it different enough that it's actually a new work or not?
And then there's this huge issue about explainability and interpretability within machine learning, which is, do we understand why the system is actually saying the thing it did? So this idea of being able to link back to data that was training it. And so lineage issues, data tracking, all that type of stuff becomes an issue.
And so this is meant to be more of an illustration of the craziness of how we need to deal with data within the machine learning world.
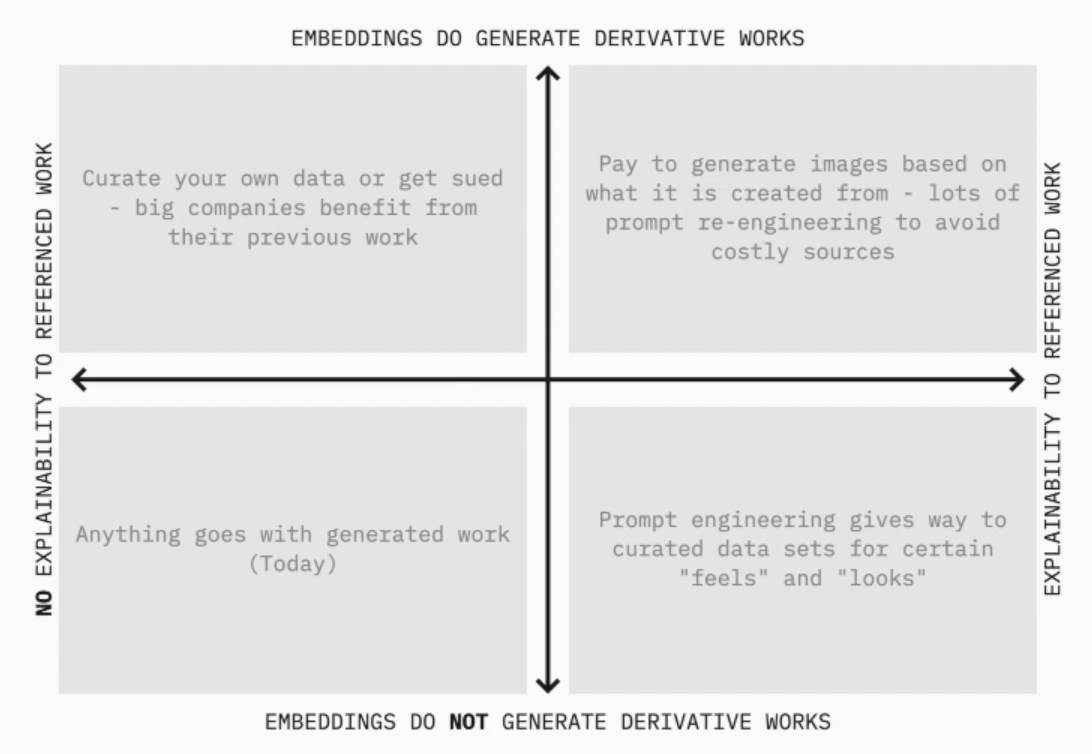
So, the world we live in today is based on this two by two right here:

Anything goes with generated work. Midjourney, DALL·E, ChatGPT, and GPT are trained on lots and lots of data that are considered to not be derivative works as embeddings. And there’s almost zero explainability for why these things do this stuff. So that's where we are today.
But if we start to think about the way that the future could start to unravel based on these different scenarios, we can start to get into this world with prompt engineering, which is a way to create better text to have a machine learning system do something.
If it’s not a derivative work and explainability is good, you start to understand how all of this data actually impacts the output of the model in some way and you can then do a better and better job of curating the output of that model.
But if we get into this world where embeddings are derivative works, you can get sued for using someone else's data, and there's no explainability, you then have to take what's referred to as a very data-centric model within the machine learning world. So you have to curate all of your own data to be able to do anything, otherwise, you get sued.
Large businesses that create lots of data or have lots of data like Disney, for example, become very advantageous in this particular world.
And then finally, if embeddings do generate derivative works and have explainability, you start to get to a weirder place where you pay based on the inspirations that create this output model.
So this is just meant to say that there's a lot of uncertainty right now about the regulation of data in the first place. But also, the fact is that there are many different places we can end up when it comes to the way we end up building things. And that's a very important kind of nuance around AI PM.
Training
The next thing I’ll talk about is training. Before, you’d write a specification or PRD, you’d have engineering implement it, you'd have QA test it, you’d put it out into the world, and then you'd have customer support give you feedback and you’d do analytics to be able to understand what's going on.
However, training doesn't work the same way. By no means is the model the only thing, but it’s an important thing in the way that it sits in situ with the rest of the system itself.
The image below is actually from Google Cloud. It's a little washed out, but what you can see here is that there are lots of boxes at the very least, and lots of arrows. It's a complex set of machinery.
We talked about training though, and the way that the PM is involved. It's not so much about specifying all the behavior, but specifying the environment by which this model is being trained within.
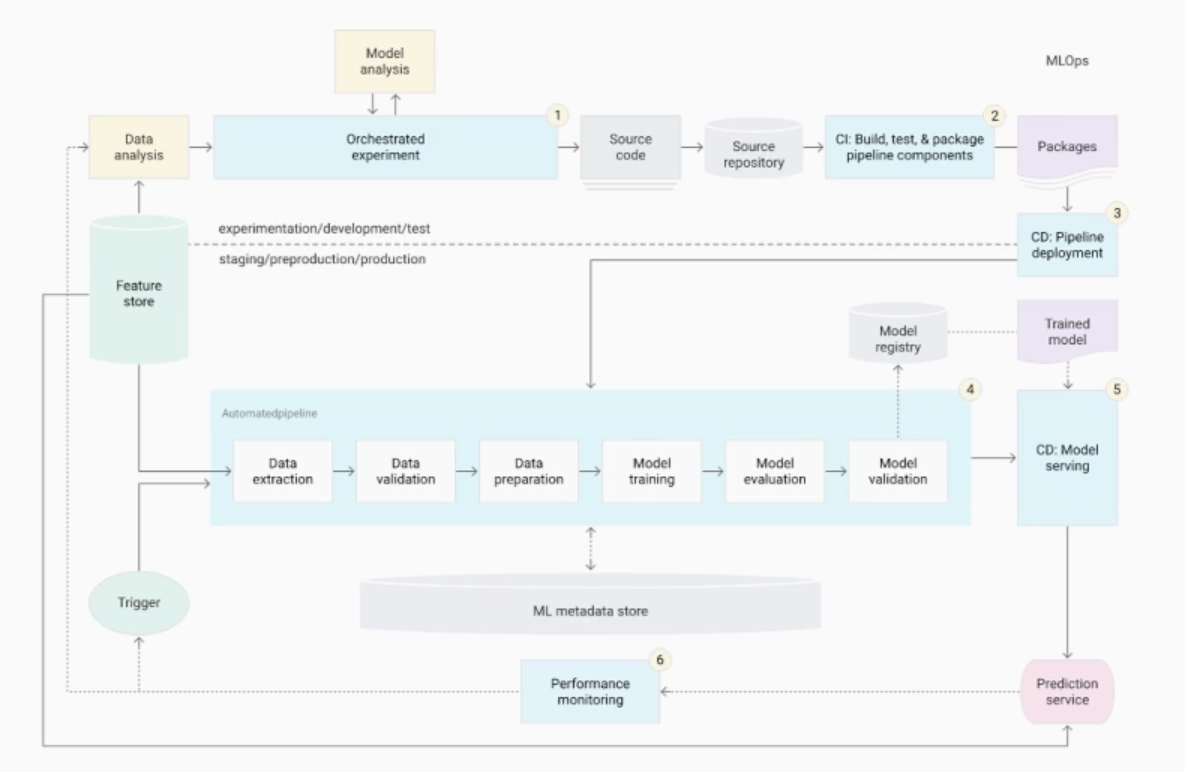
So, the first little circle is really about this idea of doing a bunch of loops to train a particular model. You're taking a dataset, you're running it through the model, you're updating the weights, and then you're getting a model that’s trained once. You may do that multiple times over epochs to be able to get a better and better model as time goes on.
But then there's another loop here, which is that you may create many different model architectures, you may use different holdouts of data, you may do all these different things to be able to create many, many different types of models that you're then going to judge on how valuable that is.
So, the PM there still isn’t necessarily doing their job. We've talked about what data may go into it, but what we're not talking about is what the evaluation actually means here. And it's not just accuracy, it's not all these things that end up being inside of the machine learning world. But we're not even at the point where we understand the impact on the customer yet.
So the next thing is this larger model, where you deploy things to the world, you get feedback from the world, and you end up using that to train better models.
You have to detect things that are referred to as drift, where you’ve trained on a current set of data but the world keeps evolving as time goes on. So you may eventually drift away from the reality of the world with your model's performance.
So, what we're doing as PMs is not specifying the exact behavior that this model should do. We're maybe putting guardrails around what it shouldn't do, but we're no longer specifying exact behaviors. We're actually creating environments by which these non-deterministic systems are being trained in some way. So that's an interesting difference, I think.
Experience
From an experience standpoint, I've done a lot of work around the intersection between things like design thinking and AI and the idea of human-computer interfaces. And what it ends up coming down to is that when these humans use a system, they're actually using it to build a mental model about how they should understand or interact with that system. And we do that with everything.
So, if we're used to using a system, we have a mental model in our head, and we're building these cognitive artifacts for people to understand what’s going on with the system so we can use it.
This also includes non-deterministic systems, though. In deterministic systems, where it’ll work the same way over and over again, we need to build new models as people to actually understand that the system may not always return the same thing that I expect or in ways that it may not expect it to behave.
It's very much dependent on trust in that system. We may have thought about trust in a very particular way when it comes to regular systems, software, and calculators. The trust we have in there is that they work the same way every single time.
But trust is different when it comes to machine learning, and this is actually a very complex subject. I'm by no means going to be able to help you solve all of your trust issues, but I can give you some pointers right now.
This is a very important paper from 1997. Back then, the only things that were really non-deterministic systems or automated systems were the military, aviation, and academic settings.
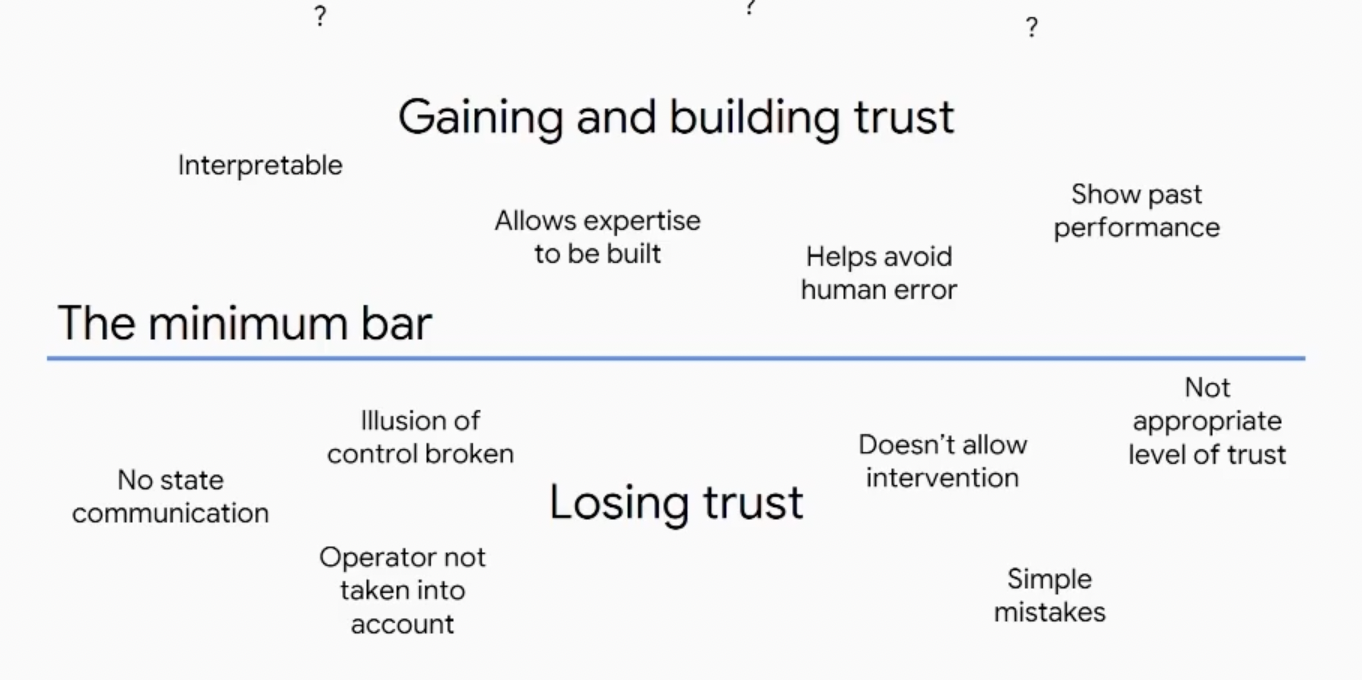
Raja Parasuraman wrote this paper about the idea of how humans build trust models with the systems. The key point about this particular paper is that it's not so much about building the most trust that you can have, but it's actually about building the right amount of trust, especially for non-deterministic systems.
So, use means essentially that I'm going to use it when I should, and I'm going to turn it off when I should. Misuse is that I use it all the time, even when I'm not supposed to. Disuse is that I don't trust it at all, so I don't ever use it. And then abuse is a very interesting one, which is that we didn't involve the actual operators of these systems to understand how they may interact with these models.

So, it ends up being a lot about how we’re building and losing trust in the right ways so that we're keeping a steady place for where the trust should be for this non-deterministic system.
There are a bunch of things that you can do to build trust. You can communicate the state of the system, you should understand what the operator’s doing and what they have to do. You allow for intervention, you shouldn’t make stupid mistakes, or if you do, you should just try not to operate in those domains.
And there's a bunch of things that we start to do to build trust with these systems. So, how do we build more interpretable systems to understand this context of a non-deterministic system and understand it to build better models around that, and help me avoid human error rather than just trying to automate my job?
This idea around trust and the right level of trust is incredibly important when it comes to building these systems. Even more important than the deterministic systems.
I’m going to give one small plug for Google, but I’d definitely recommend checking out the ‘People Plus AI Guidebook.’ It talks a lot about this type of stuff. So I definitely recommend that.
The aspect that I've been most interested in is: how do we start to build the interfaces by which people understand these things better?
Having better discussions between tech and non-tech
As PMs, we're not supposed to make technical decisions. The most hated TikTok video that someone has of me, is me saying that PMs shouldn’t be technical. And Apple user 135 very much thinks I'm stupid for saying this. But I think the thing that we need to be doing as product managers is prioritizing this idea of discussions between tech and non-tech people.
At first, this was something that we could maybe do where we were pointing at customers, or we were talking about the way they’d actually get their job done. What are the outcomes that they're looking for?
I think we get into a weirder realm once we start to use these systems, especially things like generative systems where there's not always the right use of this particular system for a particular use case.
This image below is a really great LinkedIn post for generative systems. So things like GPT, ChatGPT, Bard, all these systems that end up generating text. There are things that they can do very well that require high fluency, which means simulation of the English language or regular language. And then there's this idea of accuracy or not.
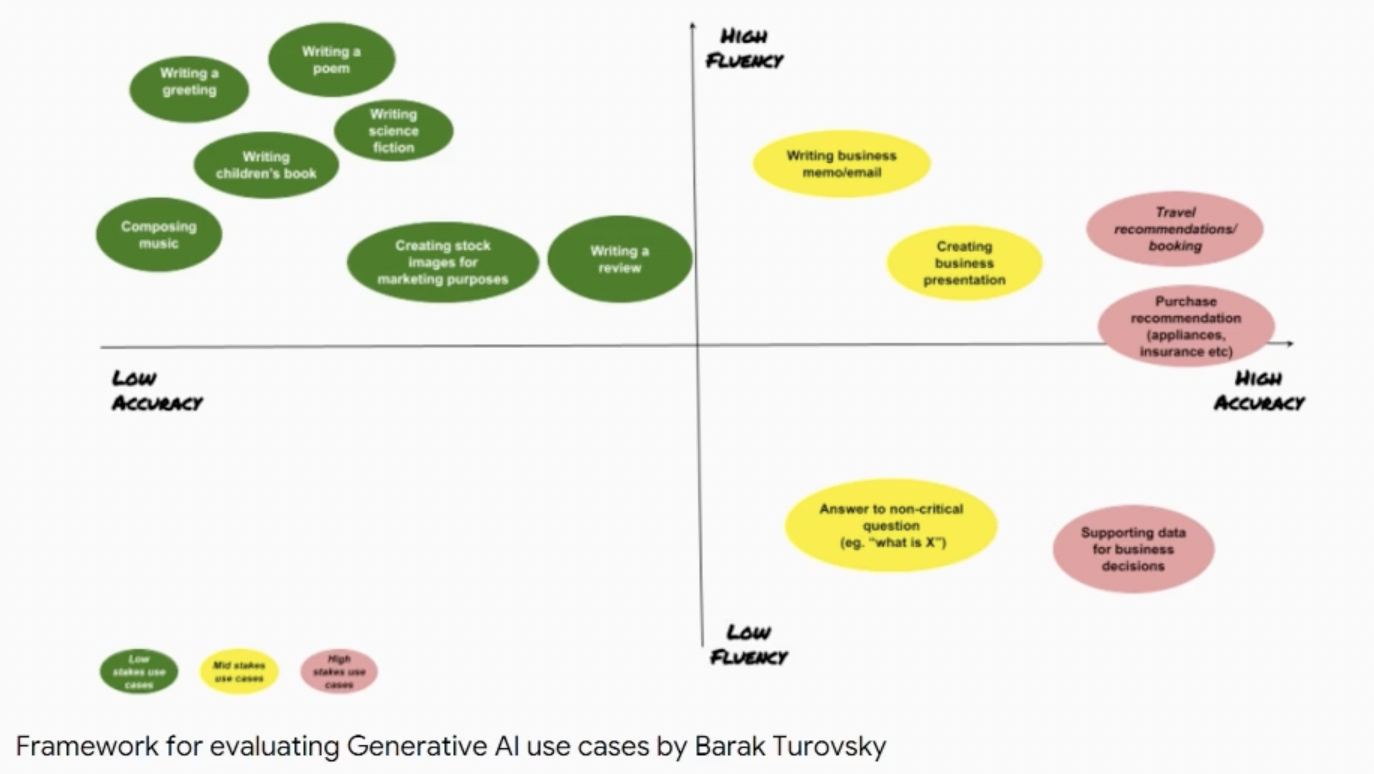
I think there are some interesting things through analogy, characteristics of problems matched to technologies, and things like that, but I think what we need to be getting back to is this concept of this technology isn’t fit for this particular use case.
Even though it can synthesize language, it's probably not the best for travel recommendations because it needs to use factual data to be able to give you an actual travel recommendation. Or the idea of purchase recommendations about appliances. If it doesn't know about an appliance that just came out, how can it give you an appropriate recommendation?
So, in those cases, we should be having a better discussion about what characteristics we should care about here. In this case, the characteristics that this particular article starts talking about are, how well should it simulate human language? How accurate does it need to be about the facts? And then how much of an impact would a mistake make on these things?
So, I think we need to have more of these types of discussions.
One way that I've had this type of discussion is I did a workshop at South by Southwest, and I have an article that you can find online about this. It was titled, ‘How does the Roomba really feel about dog poop?’
At this workshop, we were trying to have discussions through what was referred to as animistic design, and roleplay. In particular, I want to talk about this concept of roleplay.
We personify technology in a lot of ways, We shouldn't, we should try not to, but it’s also much easier for us to understand the expectations between two human beings than it is for us to understand the expectations of a human and a machine.
In this particular case, for this workshop, I had everybody pretend to be a Roomba or a Google Home Hub, or something like that. They interacted with each other and the meatbags, which were these really annoying people hanging out in the households.
And actually, the person who ended up playing the Roomba got the dog poop award, but they said that they were actually afraid of it. And that's interesting. We don't necessarily need to say that Roombas should be afraid of dog poop, but they're not built to actually work on that issue.
So, these types of discussions between humans start making much more sense when we start to do things like roleplay. We start to have these discussions in a way that regular people, or at least stakeholders or subject matter experts, can now talk to the technical experts about these particular things.
So, I think just in closing, I want to make a suggestion to everybody here. I know that right now, everything has to have AI in front of it, even your job titles. But can we actually just say experience instead, and start to use that as the terminology rather than AI and machine learning and any other technical concept?



Become a PLA Insider
Thank you for subscribing
Get exclusive insights, frameworks, and strategies from product leaders driving real business impact.
An email has been successfully sent to confirm your subscription.
 Follow us on LinkedIn
Follow us on LinkedIn


